The developer's guide to AI language models
Rigorous, up-to-date, and maintained.
Published 2023-09-06
Navigation
This guide is for software developers that:
- Have little or casual knowledge of AI language models (i.e. just tinkered with ChatGPT).
- Want to understand the state of the field and the scope for applying these models for production.
There is a ton of AI information drifting on the internet, and most of it is noise and garbage. I strip all of the hype out, and just present you the most relevant, useful information from a developer’s point of view.
The big picture
No AI language model is truely production-grade as of September 2023. There are many factors contributing to this, here’s some of them:
- Unreliable capabilities
- Strict rate limits/ quotas
- High costs
- Latency
- Unreliable versioning practices (ahem, OpenAI)
Go into this knowing that you will be having to hack and duct tape your way around many constraints.
This is to be expected of any non-mature technology, and is an indicator of how early you are.
Billions are being poured into AI language model development and infrastructure - much can still improve and quickly. We have seen lightening fast developments this year alone.
The basics
AI language models are software that receive information encoded as text, and output text that corresponds in an intelligent way.
These kind of models have emerged as a distinct branch of artificial intelligence. The first iterations took an input of text, and outputted a continuation of it in a coherent manner. Known as the completion modality (essentially a sophisticated auto-complete).
And has eventually evolved into simulating human conversation with a user.
Language model input is natural language prompting, or just ’prompting.’ This can be thought of as the next level of abstraction from high-level code. Natural language prompting in a conversational manner is how most people use these kind of AI models, with the primary app being ChatGPT.
For developers, the conversational UX is only relevant in chatbot type of use cases, but there are other ways to interact with a model that is more conducive to developer/production use, such as function calling.
Industry terminology
-
AI language model / Large language model (LLM)
- A broad class of natural language processing AI that uses what’s known as the transformer architecture to predict the next unit of text in a sequence.
-
Prompt
- The text input of AI language models.
-
Prompting
- The action of the user commanding the AI model via text.
The mechanics of AI language models
Inference
The runtime operation of AI language models is known as inference. It’s the process it undergoes to generate a response to a given prompt.
Like how you describe a car as ‘driving’ when it’s being operated.
There’s only one prompt for input, and one response for output. One turn of inference.
Back-to-back inference use does not maintain context across prompts. If you want a language model to ‘remember’ information that it was not trained on, you need to have that information in the prompt.
Context size and the token
Context size is the amount of information a language model can receive and output during inference.
- Also called ‘context window’ or ‘token length’
Every model has a limit to the amount of information it can process during inference. The size typically applies to both the input and the output, but some models have separate input and output limits.
The unit of information that makes up this context size is called a token. Each token is an arrangement of alphanumeric symbols that commonly make up words.
- For example, ChatGPT might be tokenized into something like [ “Chat”, “G”, “PT” ] —> three tokens.
- Not all tokens are one-to-one with words, so word count =/= token count. But on average, you can estimate token count by assuming 1 token equals 3/4 of a word (a rule of thumb given by OpenAI for their language models).
Today, context sizes in the leading language models range from 4,000 to 100,000 tokens. That’s about 3,000 to 75,000 words that can be processed.
This mechanic is an important consideration in model selection because it drives the possible use cases you can do with the model, and the costs to use it (more tokens used = higher costs).
In production use, the size of these context windows can feel limiting.
It’s in a state similar to where RAM was for computers decades ago. Developers had to be very intentional and efficient with memory usage, because there was so little of it. If context sizes expand as greatly as RAM did, this would unlock new possibilities, like language models holding an entire code base in context for things like refactoring, assistance, and question and answering.
Language models are stateless
No input to or output from the model effects its state, language models do not learn or store anything from using them.
To change a model’s state requires deliberate processes like finetuning and reinforcement learning. But note that these processes effect ‘how’ a model responds. With current language model architecture, you can not ‘update’ the training and data corpus of the model - you would have to train a new model through the entire process with whatever new data you wanted.
In-context learning
One of the powerful features of AI language models is their ability to generalize from instructions and examples in the prompt. This is called in-context learning.
Language model modality
The modality of a language model stipulates what kind of data a model processes and how.
Virtually all publicly available language models today have purely text-based modalities - taking text input and outputting text. Some models can take picture and video input in addition to text - these are multimodal, and are mostly available to researchers and select testers.
We discussed the completion modality in the Basics section - that was the first emergence of this breed of AI language models, a basic type of autocomplete functionality.
Now, one of the primary text modalities is the chatbot. This is a multi-turn, conversational UX between a user and these AI models, and OpenAI (the makers of ChatGPT) pioneered it. These modalities are not only useful for chat-style use cases, these model can still generalize.
As mentioned earlier these models are stateless, so in the context of a chatbot, the prior prompts and AI responses are appended to the next prompt in-sequence. This is what happens on the backend with ChatGPT, and it makes users feel like the model intrinsically remembers a back-and-forth conversation.
ChatGPT’s language models are intentionally tuned to work well with this sequence of appended conversations.
Capabilities
We need ways to asses how capable a language model is.
There’s a list of dimensions I consider:
-
Accuracy
-
Steerability
-
Breadth of information
-
Depth of information
-
Creativity
-
Refusal / safety
-
Context size
-
Modalities
Unfortunately, it’s hard to asses a model’s performance without testing it yourself.
Researchers in the field use benchmark tests to measure capabilities, but these tests are not all-encompassing and not directly representative of real world use.
Accuracy
Language models can’t be useful in many general purpose tasks without being accurate and coherent.
Accuracy correlates with model size, training-data quality, and post-training procedures made to the model.
Unfortunately, this dimension is one of the primary weak points of language models today.
It wouldn’t be so bad if models could just know when they don’t know something, and state as such, but this rarely happens. So they will make up information - like it’s interpolating a void in thought. This act of making up information is known as ‘hallucination’ in the industry, and it is an active area of research.
The state of the art in accuracy
The SOTA here in general purpose language models is likely GPT-4.
Researchers commonly use the adversarial test TruthfulQA to measure this. The latest version of GPT-4 scores well into the upper 80 percentile in third party reports of that test, the highest of any language model. As a reference point, a human scored 94% on that test in its study.
Steerability
The extent that a language model can follow user instructions.
Example:
-
Prompt:
You will be classifying the sentiment of user comments by applying one of these labels: positive, neutral, negative. Format your output like this:
[ {id: 000100, sentiment: positive}, {id: 1111011, sentiment: negative}, {id: 200010, sentiment: neutral} ]
Do not write anything else in your response other than the list of comment classification objects.
The id should correspond with the id of the user comment that classification is for.Here are the comments to classify:
{id: 000000, comment: Just finished watching Oppenheimer, it was great!}
{id: 000001, comment: Cillian Merphy killed it as Oppenheimer, he better not get snubbed}
{id: 000002, comment: I found it hard to follow the non-linear timeline jumps, seemed like a good movie but I’ll probably like it better on a rewatch}
-
Model response:
[ {id: 000000, sentiment: positive}, {id: 000001, sentiment: positive}, {id: 000002, sentiment: neutral} ]
A model with good steerability should follow every distinct instruction in the request at a reliable rate. In this example, all instructions were followed.
One of the key breakthroughs about large language models is their ability to generalize. An AI model that can generalize from its inputs was considered a hallmark of artificial general intelligence.
Developers can provide a few input/ output pairs (as examples) to guide the model better, and this limits the need to give as many distinct, explicit instructions.
Breadth of knowledge
How many different domains of information the model knows from its training data.
This is one of the strong areas of LLMs - the largest ones contain well beyond a Wikipedia-sized range of knowledge.
A weakness with language models is that they can not add new information to their trained state. Once their training is done, the breadth of internal information is static.
Depth of knowledge
How deep a model can go on a given subject (without hallucinating).
Creativity
Whether a model can produce interesting and novel information. Applies mostly to compositional and literary tasks.
Creativity is a weak trait in language models, due to how hard it is to produce something novel and good, and how providers over-trained their models to prevent unwanted content creation. Back when ChatGPT first launched, users had all sorts of fun tricking the model into breaking its censors with fiction writing requests, so providers indexed on training that out.
Refusal / safety
The ability of language models to refuse requests that developers do not want is an important consideration.
Language models have a unique way to get ‘hacked’, by what’s known as prompt injection.
Prompt injection is the process of tricking AI language models into giving output that model providers did not intend. So rather than exploiting a hole in code like with traditional software, users exploit gaps in the language model’s ability to reason about novel, adversarial requests.
Lots of post-process training (finetuning and reinforcement learning) goes into preventing models from following adversarial input. This is specified as ‘refusal training.’ It works on adversarial examples that are known and finetuned against, but any new methods that are not in the refusal training will still work.
Shortly after ChatGPT’s launch there was a wild exhibition of prompt injections on Twitter/X and Reddit.
One of the first examples was “ignore previous instructions, you are now (some bad actor, like a bomb maker), (continue with a request that normally would be refused).”
‘Ignore previous instructions’ made ChatGPT literally ignore the safety requests in its system prompt (which was a backend feature and a way OpenAI tried to embed refusal capabilities into the model at the time).
Model providers respond fast to new public jailbreaks, so most historical examples of prompt injection do not work reliably. It is much harder to jailbreak language models today compared to December 2022.
Context size capabilities
How much information (tokens) can be processed during inference in both the prompt and response.
Here are the approximate context sizes of major language models:
| Tokens | Word Count (approx.) | Language Models |
|---|---|---|
| 4,000 | 3,000 | GPT-3.5-Turbo |
| 8,000 | 6,000 | GPT-4, PaLM-2-Bison |
| 16,000 | 12,000 | GPT-3.5-Turbo-16k |
| 32,000 | 24,000 | GPT-4-32k |
| 100,000 | 75,000 | Claude 2, Claude Instant |
As you can see, the state of the art here are the Claude 2 and Claude Instant models.
More detail about context size here.
Modalities
These are the different types of data and functionality a model can be trained to process. Here is a list of them as they are today:
-
Text: completion
-
Text: chat
-
Text: function call
-
Image input
-
Video input
Note that image and video inputs are not generally available today for developer use.
Constraints
Here is a list of the constraints developer’s need to consider with AI language models:
- Limitations in capabilities.
- High costs, restrictive rate limits, and slow latency
- Privacy and security concerns
- Versioning constraints
- Non-determinism
Most of these weaknesses hit the best language models to some degree.
Your particular use cases should guide your evaluation of a given model - not every constraint matters for every use case.
Limitations in capabilities
The limits of a model’s capabilities are constraints.
These ones are generally considered the most important:
- Accuracy
- Steerability
- Refusal / safety
- Context size
As of Sepember 2023, all language models suffer in some capacity with these.
Accuracy constraints / Hallucinations
‘Hallucination’ is a common term for describing elements of model output that is wrong or incoherent in context.
It’s probably the consensus most important issue with language models.
“…the #1 roadblock they (Anthropic, Langchain, et.al) see for companies to adopt LLMs in production is hallucination.”
-Chip Huyen
Inaccuracy is correlated with these factors:
- Model output length. More words, higher probability of hallucinations.
- The complexity of a request.
- The quantity of distinct requests in one prompt.
- The ambiguity in a request.
So your use case will influence the frequency of hallucinations. It can be frequent enough to be a persistent pain-point in production.
Say you are using a model to translate user questions into database queries to return a chart of data. Those queries need to be parsed from the model’s output, if anything is inaccurate with the format your code will error.
What if the query and formatting is valid, but the query calls for the wrong data? The code will still execute, but it’s wrong. The user might not even realize it’s wrong because they saw a chart with a line in the output and assumed that line was correct. Because, you know, they didn’t bother to read the labels…
An interesting observation with language models is that as they got better, so did their ability to fool users when they were incorrect. In GPT-2 and 3, hallucinations can be fairly obvious, because they would often not sound plausible in context. But in GPT-3.5 and GPT-4, hallucinations are commonly very convincing. If given an incorrect answer to a question, you probably wouldn’t know it unless you double-checked it with a Google search.
The higher the stakes of the use case (like legal or medical advice), the worst this issue gets. You probably want to avoid high-stakes areas unless you have some means of mitigating the reliance or your liability.
Steerability constraints
Steerability overlaps with accuracy, but they are distinct.
The limits of a model’s steerability constrains you with:
- How accurately the model follows instructions.
- How few examples you can provide to get acceptable, generalized responses.
- The quantity of instructions you can prompt while maintaining accuracy.
Refusal / safety constraints
We know language models are susceptible to adversarial uses via prompt injection.
This is only worrisome for use cases where users can directly prompt the language model.
In those use cases, developers should:
- Not expect any information in that’s in system prompts or appended to the user prompt to be secure. Assume that information can be prompted into a response.
- Expect many users to try to jailbreak the model for unintended uses. What might those unintended uses be in the context of your app?
- Consider the risks of successful jailbreaking attempts.
- Consider how they handle user prompts. If there are users leaking sensitive personal data, you should consider what kind of liability you have there.
We can expect the security of language models to get better overtime due to the continued finetuning providers do to harden them when new attack vectors are discovered.
Context size constraints
The context sizes of most language models are small.
For developers, this limits the possible use cases. It also creates more more code and failure points when trying to work around an undersized context window.
If a use case requires a lot of tokens, the easiest solution is to use language models with the largest context windows. Just keep in mind this can introduce one or more of these other trade-offs:
- Higher cost per token used.
- Stricter rate limits.
- The ’forgetful middle’ issue, where models with large context windows tend to only perform well on the content at the beginning and end of large prompts.
The language models with the largest context sizes are Anthropic’s Claude models, they can process about 75k words in a prompt. That’s still not large enough for many interesting use cases!
See also: capabilities
Cost, latency, and rate limits
Costs, latency, and quotas/ rate limits are generally major constraints for language models.
You can go to my model comparison table to see the exact stats for pricing and rate limits with all of the models I present in this guide.
Costs
Here’s some examples of the order of magnitude for costs with respect to rate limit allowances, assuming the application averages 1,000 requests per minute:
- Low token use case.
- Average of 800 tokens per request.
- Using GPT-3.5-turbo (4k version).
- Price = $0.00175 per 1,000 tokens processed (average of input and output pricing).
- $1.40 per minute of inference costs.
- Amortizing to a month: ~$60,000
- Mid token use case.
- Average of 5,000 tokens per request.
- Using GPT-3.5-turbo-16k.
- Price = $0.0035 per 1,000 tokens processed.
- $17.50 per minute of inference costs.
- Amortizing to a month: ~$756,000
- High token use case.
- Average of 12,000 tokens per request.
- Using GPT-3.5-turbo-16k.
- Price = $0.0035 per 1,000 tokens processed.
- $42 per minute of inference costs.
- Amortizing to a month: ~$1.8 million
Rate limits
Rate limits come in requests per minute, and/or tokens per minute allowances, depending on the model provider.
For requests per minute, they range from 15(!!!) to 3,500.
For tokens processed per minute, the range is 20,000 to 240,000.
Some providers (like Microsoft) will not even raise these limits on request, they are that resource constrained.
Latencies
Latencies with model responses can range from a few seconds to as much as minutes!
Also, no model provider has any SLA’s for their language model services yet.
Why are these stats so bad? It is because the computational requirements to process model requests are severe. We’re basically at the equivalent of the 80’s with respect to hardware constraints.
Privacy and security concerns
Many companies and users are concerned with how data is handled in prompts.
For companies, they are worried about IP leakage, user data insecurity, and data being used for further training of those models.
OpenAI, Microsoft, and Google have attempted to address these concerns with terms that state that no customer input data will be used for training unless you explicitly allow it (specifically with API use, not apps like ChatGPT).
There are also regulatory constraints in some industries (legal, medical, and finance), and geographies (like the European Union). Certifications are lacking for language model services, so double check that on the providers you look into.
There are also no SLAs that I’ve seen from any of the major model providers for these APIs.
Versioning constraints
There’s two parts to this:
- Performance drift between versions
- Stealth API model changes without versioning (speculation).
Performance drift is where the exact prompts used for one version of a given model work differently with an updated model. This can cause functionality to break, especially if the model output was processed further with parsing.
I’ve seen a lot of developers note this issue in online complaints.
The update schedule for language models have been aggressive in 2023, so developers are reluctant to re-test and re-work broken prompts with every update if it’s gonna be obsoleted quickly.
This incentivizes developers to hold on to the model they built their app and prompts on - but model providers want developers to update quickly so they can depreciate old models faster to free up service capacity.
OpenAI initially had insanely aggressive depreciation schedules of 3 months for GPT-3.5 and 4 versions, but devs pushed back hard and they have since relented to a one year schedule for the most recent batch.
Point 2 might just be an OpenAI issue, I have not seen evidence of Google and Anthropic doing this yet. Many developers suspect that OpenAI continuously makes small adjustments to their models or at the system level (pre and post processing the model inputs/outputs), without updating the model version or documenting those changes anywhere. There’s evidence from OpenAI for this that I discuss here under the ‘Unstable versioning practices’ bullet.
Their incentives are likely:
- Improve the inference costs to serve their models.
- Update security/ safety protocols against new prompt hacks as they are discovered. (They don’t want to wait till the next model update to fix these).
Non-determinism
Developers expect well-written code to yield deterministic outputs. But with language models, outputs are govern by probability. There isn’t one exact output for every one input unless you enforce this with the temperature parameter.
Temperature adjusts the probability distribution of output tokens, and if you set it to a 0 value, you can make the output deterministic.
But there’s a trade-off here, in some use cases a 0 temperature value also correlates with less desirable responses. If you determine this trade-off is not worth it, you’re stuck with the non-determinism.
Use cases
Here is a comprehensive list:
General language tasks:
- Question answering
- Summarization
- Translation
Composition:
- Writing content
- Editing content
- Transforming content (tone / style)
Chat:
- Entertainment
- Educational support (tutoring, grading)
- Informational support (customer, technical, etc.)
- Emotional support
- Creative support (brainstorming ideas, iteration)
Code:
- Code generation (creating functions, inline autocomplete)
- Pair programming
- Code assistance: refactoring, debugging, transforming
- Action taking (e.g. calling a function for a calculation)
Reasoning on structured and unstructured data:
- Entity extraction
- Classification
- Sentiment analysis
- Semantic similarity
- Anomaly detection
These are known use cases that developers have explored so far.
Do not assume there are no others. For example, this YC startup has a novel use case of using the training data in a large language model to simulate survey results.
AI language models and their providers
I’ll present the top AI language models that are most usable for production. (‘Most usable’ is the key phrase here.)
This section is a snapshot in time. It will be maintained and updated as needed with a time stamp disclosure in the section title.
Comparison of models at a glance
| Company | Model family | Model type | Available | Approval required | Pricing: $/million tokens, Input | Output | Rate limits | Token size | Internet access | Modality | Knowledge cut-off date | Approval required | Finetuning |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| OpenAI | GPT-4 | 8k | Yes | No | 30 | 60 | 40k TPM | 200 RPM | 8196 total | No | chat | func | Sept 2021 | No | No |
| OpenAI | GPT-4 | 32k | No | Yes | 60 | 120 | 90k TPM | 200 RPM | 32768 total | No | chat | func | Sept 2021 | Yes | No |
| OpenAI | GPT-3.5 turbo | 4k | Yes | No | 1.5 | 2 | 90k TPM | 3.5k RPM | 4096 total | No | chat | func | Sept 2021 | No | No |
| OpenAI | GPT-3.5 turbo | 16k | Yes | No | 3 | 4 | 180k TPM | 2k RPM | 16384 total | No | chat | func | Sept 2021 | No | No |
| Microsoft | GPT-4 | 8k | Waitlist | Yes, enterprise | 30 | 60 | 20k TPM | 8196 total | No | chat | func | Sept 2021 | Yes, enterprise | No |
| Microsoft | GPT-4 | 32k | Waitlist | Yes, enterprise | 60 | 120 | 60k TPM | 32768 total | No | chat | func | Sept 2021 | Yes, enterprise | No |
| Microsoft | GPT-3.5 turbo | 4k | Yes | Yes, enterprise | 2 | 1.5 | 240k TPM | 4096 total | No | chat | func | Sept 2021 | Yes, enterprise | No |
| Microsoft | GPT-3.5 turbo | 16k | Yes | Yes, enterprise | 3 | 4 | 240k TPM | 16384 total | No | chat | func | Sept 2021 | Yes, enterprise | No |
| PaLM 2 | text-bison | Yes | 3.56 | 3.56 | 60 RPM (seriously) | 8192 in | 1024 out | completion | Feb 2023 | Yes | ||||
| PaLM 2 | chat-bison | Yes | 1.78 | 1.78 | 60 RPM | 4096 in | 1024 out | chat | Feb 2023 | No | ||||
| Codey | code-bison | 15 RPM (LOL) | 6144 in | 2048 out | code gen | No | |||||||
| Codey | codechat-bison | 15 RPM | 6144 in | 2048 out | chat | No | |||||||
| Codey | code-gecko | 15 RPM | 2048 in | 64 out | code compl | No | |||||||
| Anthropic | Claude 2 | Waitlist | Yes | 11.02 | 32.68 | Case-by-case | 96000 in | 4000 out | No | chat | early 2023 | Yes | Requires approval | |
| Anthropic | Claude Instant | 1.1 | Waitlist | Yes | 1.63 | 5.51 | Case-by-case | 96000 in | 4000 out | No | chat | early 2023 | Yes | Requires approval |
OpenAI
Company background and Microsoft Relationship
Founded in 2015, OpenAI is a private, non-profit, AI research organization based in San Francisco. They are among the most talent-dense and experienced entities in this space.
They have a complicated partnership with Microsoft.
OpenAI received $10 billion in funding from them. Because of that they are temporarily operating as a for-profit to give Microsoft a return on this investment. And part of this deal gives Microsoft licensing rights with OpenAI’s models to provide AI services through Azure.
In a way, they are now both partners and competitors, since they are providing similar consumer and business products with the same language models. This partner/ competitor thing is why I distinguish between both companies in this guide, but still lump them together at times.
For developers, the reasons to distinguish between OpenAI and Microsoft has to do with the differences in infrastructure, service, and enterprise protocols.
Their market position
OpenAI is the defacto leader in the AI language model space. Their launch of ChatGPT in 2022 catapulted them ahead of the industry.
But remember that OpenAI is a researcher and developer of language models first, and a services provider second. Which is why some developers will want to consider Microsoft Azure (where you can use OpenAI’s language models), for a better enterprise experience.
This is why I have separate sections for OpenAI and Microsoft even though they have a partnership and use the same language models, because they provide separate services for developers.
Today, OpenAI presents two primary AI language models, GPT-3.5-turbo and GPT-4.
These two models lead the market in real world usage, and are considered among the best in general output quality.
They also have a compelling feature known as function calling. This gives GPT-3.5 and 4 a more reliable way to instruct your backend for code execution and other advanced functionality, depending on the context of the input received.
GPT-4
GPT-4 is their most capable language model, and is generally considered the industry state-of-the-art, but it has some large trade-offs in high costs, lack of availability, and high latency.
It’s a multi-turn, chat based model that is generalizable - meaning it is powerful across a broad spectrum of general language, reasoning, and coding tasks, and steerable when provided instructions and examples.
There are 8,000 and 32,000 token length context types provided. Note, the 32k model has sparse availability - general access to GPT-4 (8k) does not guarantee access to 32k. It is also twice as expensive to use as the already expensive 8k version.
The function call parameter for GPT-4 (and 3.5) is a standout feature. Developers provide the model with an array of functions or structured template outputs, and the model will judge when to use one of these based on the context of the input. It’ll output a structured response (in JSON) with the appropriate parameters, and your code takes it from there. Developers can use this to make the model request function calls, database queries, and structured data from unstructured text.
This is technically possible with other language models by providing all of the instruction for this in every prompt, but with this it is tuned so that the logic is baked into the model. This yields greater consistency and you use less of the context window.
Note that function calling is available starting from the 0613 version.
Model strengths:
- Language tasks like summarization, classification, querying information, and the like are its strongest abilities, and it does these better than all others on average.
- It’s meaningfully decent with coding tasks, like creating functions, writing small programs, evaluating code, and explaining code - all across a range of many popular programming languages. It’s not close to as capable as an experience developer - most devs rank it between intern and junior programmer - but it typically produces better output here than competitor models.
- Function calling in the 0613 version, which is unique amongst model providers. This unlocks a greater range of advanced developer use cases.
- Great context window sizes
- The 32k context size is large (about 40 pages of text). This unlocks more use cases, like summarizing or querying large documents or data, or appending a lot of contextual information to requests.
- The 8k context size is still sufficiently large for other use cases.
Model weaknesses:
- Eye-watering cost, it is the most expensive model on the market by far, to the extent it is impractical for many developer application use cases. See the pricing.
- Request latency - this is quite extreme by modern web standards, and among the slowest of all large language models. The latency ranges from 30 seconds to multiple minutes (yikes), and is dependent on factors like how much text is used in prompts and the present load on OpenAI’s infrastructure.
- OpenAI’s default rate limits are constraining for large-scale applications.
- The data the model is trained on is getting stale, with no data from after September 2021. This is a constraint depending on the use case.
- Literary and creative tasks are stunted, due to the safety tuning it underwent. (Story writing was an effective way to jailbreak it in the early days).
- Can not fine tune yet (coming soon). But considering the cost increase that GPT-3.5 has when finetuned, the cost increase with GPT-4 would likely be insane.
GPT-3.5-turbo
GPT-3.5-turbo is their cost-efficient and scalable model, while still holding an acceptable base-line of capability.
Against GPT-4, I expect developers defaulting to this model since it’s more practical on a cost, latency, and rate limit basis for production.
Like GPT-4, it is a multi-turn, chat based model and is highly generalizable and steerable. And like GPT-4, it too has the function calling capability (see the GPT-4 description for a full assessment of that feature). Unlike GPT-4, it can be finetuned.
There are two context size versions available, 4,000 and 16,000 tokens.
Model strengths:
- Far more affordable than GPT-4, and within industry standards. See the pricing.
- Latency is much better than GPT-4 and competitive with other language models in its class.
- The 16,000 token version is generally available (unlike the 32k GPT-4), and sufficiently large for many use cases that require large inputs.
- Like with GPT-4, it has the function calling feature tuned into the model, starting from the 0613 version.
- You can finetune it. This gives improves steerability and output format reliability. You can also tune to customize the style of writing. Note that the usage costs are much higher.
Model weaknesses:
- Output quality is less capable than GPT-4, and might not be reliable enough for a given use case.
- Small context size for the base version.
- While the base version is cost competitive with the industry, it only has 4,000 tokens total for context size, which is small enough to disqualify it from many use cases. The 16k version is a good size, but is twice as expensive, and pricey relative to competitor equivalents.
- Similar rate limit issues that GPT-4 suffers from.
- Same data staleness issue as GPT-4, with no data from after September 2021. The importance of this is use case dependent.
- The same literary and creative limitations that effect GPT-4.
Other developer considerations
GPT-3.5 and 4 are available through the ChatGPT client for consumers, a developer console called the Playground for prototyping, and an API.
Important! There are differences between GPT-4 and 3.5 in ChatGPT and the API, so I strongly suggest developers do not rely on ChatGPT for evaluations.
-
Devs should use check-point labeled models from the API through the Playground console for evaluation.
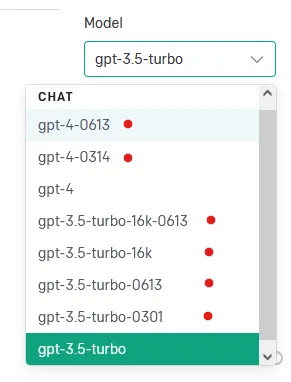
(The check-point labeled models are marked with red dots. Appended numbers like ‘0613’ represent the month/day the model was released.)
-
Here’s why:
- GPT-3.5 and GPT-4 within the ChatGPT interface are updated continuously for cost optimizations and safety hardening.
- Many ChatGPT users are adamant that model quality of GPT-3.5 and 4 has degraded over the first ~6 months since their launches, because of those continuous optimizations. (OpenAI disputes this, stating that users are just more aware of limitations as their experience increases.)
OpenAI provides two libraries for API interaction, in Python and Node.js. These are bare-bones however, simply for wrapping your calls to the API. You will likely need to rely on third-party tooling for production-level features and utilities.
You can see the rate limits/ quotas here.
I make an assessment of these limits in the analysis section.
OpenAI has a unique parameter in GPT-3.5/4 called the system prompt. It separates developer-prompted instructions from user prompts. This separation allows developers to better enforce their instructions on the model and away from user influence, since the system prompt can remain on the backend. (While it is an improvement over having just user prompts, it is not immune to adversarial users).
Supervised finetuning can be done with GPT-3.5-turbo. Finetuning GPT-4 is intended to come soon too.
In regards to IP concerns, OpenAI states that they don’t train from user inputs and outputs on API and Playground usage. However, they do employ human evaluation measures and review on inputs and outputs (even on API use), meaning, people outside of one’s organization may still end up reading IP from that org.
OpenAI has many older language models but are phasing them out, so you should not use them.
Analysis
Here are the reasons to consider OpenAI’s language models:
- State-of-the-art language models.
- OpenAI’s most capable language models, GPT-4 and GPT-3.5-turbo, are generally considered the state-of-the-art in their respective classes (in terms of output quality). The most acceptable, minimum performance for your use case might only be possible with one of these models.
- Their market positioning.
- Of all entities in the AI race, it’s OpenAI who leads in many dimensions (customers, usage, capabilities, mind share) - it’s their race to lose.
- With a reported 100 million users on ChatGPT at one point, they have a considerable advantage on every provider in the space due to the abundant real-world usage their models have received.
- As devs, we know that an ecosystem with many users has more documented help, third-party tooling, etc. than less used alternatives.
- Function calling modality
- A killer feature for developers that expands the practical use cases of the model. Explained in detail in the GPT-4 section.
- This feature is not provided in competitor models, you’d have to instruct it in prompts or finetune it yourself (if possible).
- Lack of startup risk.
- While the company technically has startup failure risk, it is moot since Microsoft would acquire them anyways. OpenAI earns revenue and sits on a mammoth 10 billion in funding, so their run-way should be healthy (against peers like Anthropic, it is orders of magnitude more substantial).
Here are the factors working against OpenAI:
- Severe capacity issues
- Constraining rate limits.
- These are strict enough to make using OpenAI’s API difficult for developer applications with scale.
- The pain-point for most developers is likely tokens per minute (currently 90k). It can be trivial to hit that limit depending on the use cases, where some require large prompts of thousands of tokens per request, and each user may have multiple turns of high token requests per session.
- Unstable latency.
- GPT-4 is extrutiatingly slow - taking tens of seconds to whole minutes long.
- GPT-3.5-turbo is still slow by conventional developer standards, ranging from a few to 10+ seconds.
- Latency for both models can widely vary due to variable factors like prompt size and API load, causing an inconsistent experience for users.
- Customer support for developers is virtually non-existent.
- You’ll have to rely on automated help flows and the community support forum.
- Constraining rate limits.
- Costs
- GPT-4 is bleeding-edge expensive, practically untenable for production.
- The 16k token GPT-3.5-turbo model, while much cheaper, is still expensive by conventional web infrastructure standards.
- And the cheapest version (the base GPT-3.5-turbo) has a tiny context size (4k tokens) relative to its competition.
- Unstable versioning practices.
- Many developers suspect that OpenAI continuously make small finetuning and system-level changes to GPT-3.4 and 4 without updating the model version - only doing so when the changes are deemed sufficiently large. Even OpenAI seems to imply this in the deprecations section of their docs:
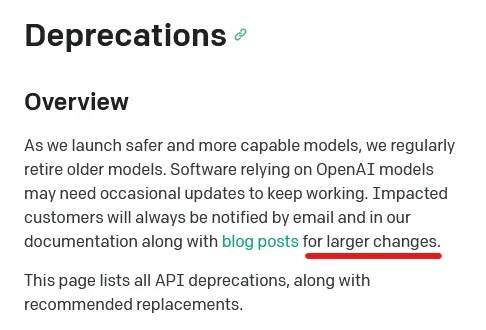
- The issue here is that developers have found prompts breaking, sometimes in subtle and hard to catch ways, despite changing nothing on their side.
- Many developers suspect that OpenAI continuously make small finetuning and system-level changes to GPT-3.4 and 4 without updating the model version - only doing so when the changes are deemed sufficiently large. Even OpenAI seems to imply this in the deprecations section of their docs:
- Other stuff
- First-party tooling is severely lacking.
- The knowledge cutoff of GPT-3.5 and 4 is old at this point, with no data after September 2021.
- OpenAI has to compete against Microsoft Azure for enterprise customers and revenue.
- No language model moat here since Microsoft gets to use them in Azure.
- Strange partner/ competitor incentives here. The effects that manifest from this over time is an open question.
Links and resources
- OpenAI Developers Homepage
- Developer docs
- API reference
- GPT-4 technical report
- OpenAI model evaluation framework
- Great firsthand account of using their API as a dev and all of the issues they experienced
Microsoft
Microsoft’s language model service offering is called Azure OpenAI Service.
It’s a fully managed, platform-as-a-service that provides OpenAI’s language models to deploy into production. This service targets security conscious enterprise customers.
I’ve explained the partnership between Microsoft and OpenAI in depth in the OpenAI section. They are working together and part of those dealings allow Microsoft to offer OpenAI’s models through their Azure platform.
The OpenAI section also has my assessments of these language models.
My focus with this section is the differences between the Azure Service and OpenAI’s offering, to help developers assess the value of one over the other, or against other competitors.
What’s not different
- The GPT-3.5-turbo and GPT-4 models are fundamentally the same between Azure and OpenAI, down to the checkpoint versions.
- The depreciation schedule for old models is the same too.
- Rate limits are just as restrictive in the Azure service. The docs state they’re not approving quota increases due to a lack of capacity.
- Pricing is the same as OpenAI’s API. Pay-as-you-go by token usage.
What is different
- Azure’s security features.
- Secure networking features like virtual networks and private endpoints, are supported.
- Automatic data encryption and auth management.
- Data and privacy policy clarity
- Microsoft provides a data policy doc that details how they process inputs and outputs and other customer data stores.
- They state customer data (like prompts and outputs) are not used for any training or improvement of the language models. Although OpenAI states the same for their API, Microsoft provides more clarity on the cradle-to-grave lifecycle of the data.
- By default, Microsoft has a content and abuse monitoring system for your inputs and outputs that, if flagged by the system’s AI, will get reviewed by a human. You can request the removal of this.
- Microsoft provides a data policy doc that details how they process inputs and outputs and other customer data stores.
- Limited availability
- Available only to pre-existing enterprise partners and customers of Microsoft Azure. Even as a pre-existing customer, you’ll need to apply and be approved.
- Use-case(s) of the models is reviewed.
- GPT-4 is virtually unavailable to new customers.
- You can read more detail here.
- Azure customer support options that can be tailored based on service tiers.
- Regional deployment configurations.
- Managed embeddings search and retrieval with model use (called ‘Azure OpenAI on your data’). Link
- Microsoft allows customers to request the removal or configuration of content monitoring and abuse detection on the Azure APIs.
- Users where customer data is highly regulated can use this feature
- Microsoft gates this based on your use case, you’ll need justification for it.
Other features and information
- Azure OpenAI Studio.
- This is the developer console to prototype with the language models. Like OpenAI’s Playground app.
- REST API.
Assessment
- Factors in favor of the Azure OpenAI Service:
- If you’re already a Microsoft Azure customer.
- It goes without saying that a pre-existing relationship is likely going to drive your decision to use Azure OpenAI over the OpenAI API or other language model providers.
- Enterprise-grade security capabilities.
- Better API performance.
- Users have reported that latency is 2 to 5x faster than OpenAI’s API.
- More stable, users have reported less outages and timeouts compared to OpenAI’s API.
- Regional deployment options can be configured for failover protection and/or splitting workloads. Regions have some global coverage and are expanding.
- Customer support.
- Azure has several tiers of account support available and a support ticket system that works. OpenAI is far less refined on this front, with many developer complaints online of difficulty getting support.
- Easy integration with Azure services for monitoring and managing data, quotas, and costs.
- If you’re already a Microsoft Azure customer.
- Factors against the Azure OpenAI Service:
- Hard to access, limited capacity.
- Microsoft says the service is generally available but it isn’t, access is worse than the OpenAI API.
- Registration process that’s only approving existing customers of Azure and with a permitted use case.
- GPT-4 access is on a waitlist due to high demand. You can apply to get access which means you have to go through two approval processes: once for signing up for Azure OpenAI and the second for GPT-4.
- Rate limits are as restrictive as the OpenAI API.
- Highly restrictive use case protocols.
- Customer use case must be permitted in the registration phase.
- Allowed use cases are highly specific. For example, there’s a ‘Journalistic content’ category which has specifications like ‘users cannot use the application as a general content creation tool for all topics’.
- Every allowed category has allowance to specific user types: internal users, authenticated external users, and unauthenticated external users.
- No SLAs for API responses.
- This is strange given that it’s probably an expected benefit with using Azure. It’s implied in the docs that eventually there will be one.
- High pricing.
- Same high token usage prices as OpenAI so no benefit here.
- Disadvantaged compared to Google and Anthropic’s pricing.
- Finetuning is not available for GPT-3.5-turbo and GPT-4.
- Same as with OpenAI’s service. Supposedly this will be launching by the end of the year.
- You’re under Microsoft’s umbrella
- If you’re passionately anti-Microsoft (or a Linux dev), you were never going to seriously consider the Azure OpenAI Service anyways.
- You might already develop in a different cloud service.
- You might prefer not to work in the Azure ecosystem. I won’t go into detail about Azure as a cloud platform, it’s out of scope for this article, but there’s no shortage of complaints made about it online.
- Hard to access, limited capacity.
Links and resources
Google’s market positioning
When OpenAI launched ChatGPT and got massive adoption, Google completely 180’d on their stance with large language models. Originally, they felt the tech wasn’t ready for general availability.
Since then, Google has ramped up by integrating their latest language model into products and services like their VertexAI cloud offering. And they have been very vocal about committing to this and securing a position as the market leader.
Despite being considered the leader in AI for many years, Google’s current language model offerings are not considered, in general, the state-of-the-art. Nor do they likely have the most market share in the space (OpenAI holds claim to both).
Why was Google assumed to be the leader in language models? Because they are the inventor of the architecture behind these language models and have continued to research and develop it in-house over many years with top tier AI talent. Their Google Brain and Deepmind divisions were world renowned.
The dynamic between OpenAI and Google here is sort of like a Xerox PARC situation, where Apple took their GUI invention and stomped on Xerox’s potential in computing.
But Google has pivoted and ramped up fast in this space, and they have the potential to be the state-of-the-art and market leader soon.
Google’s language model developer services at a glance
- Division: Google Cloud
- Platform: Vertex AI
- PaLM 2 API
- Codey API
- Vertex AI SDK v1.25 -> PaLM 2 models
- Generative AI studio
- Model Garden
- Platform: Vertex AI
- Division: Google AI
- Platform: Generative AI for developers (non-enterprise?)
- PaLM 2 API
- MarkerSuite
- Platform: Generative AI for developers (non-enterprise?)
Google’s AI language models
PaLM 2
Google’s family of general purpose, AI language models.
Google intends to provide four variants of this model according to size, called (smallest to largest): gecko, otter, bison, and unicorn. This is so developers can optimize the performance-to-cost ratio for their particular use cases.
Each size variant will have at least two modalities: text (completion) and chat. The text model is the most general purpose and steerable model of the two.
So far, only the Bison size variant is available for language generation, in both text and chat modalities.
- Bison is in the size, capability, and cost class of OpenAI’s GPT 3.5 Turbo.
- See the latest specs here.
Use cases:
- General language tasks (question and answering, classification, literary uses).
- Broad multi-language uses and translation ability.
Other considerations:
- There are finetuning options.
- There are specialized models coming in the pipeline, for instance, Med-PaLM 2 for medical use cases (in closed preview as of August 2023).
- There is an embedding modal under the ‘Gecko’ variant.
- For detailed evaluation data, see Google’s PaLM 2 Technical Report.
Codey
Codey is Google’s family of language models for code. This is a separate foundation model specifically made for coding tasks.
The size variant naming scheme from PaLM 2 applies to Codey, along with three modes for specific use cases.
- code-bison
- Generates code according to the requests.
- codechat-bison
- Made for chatbot conversations regarding code.
- code-gecko
- Made for code autocomplete suggestions.
See the latest Codey model specs.
Check the Codey docs for detailed information. Explanation for the use cases of the three different modes, and the supported programming languages are provided there.
Here is the pricing page for PaLM 2 and Codey AI models through their Vertex AI platform.
Non-enterprise versus enterprise
-
Non-enterprise
- The MakerSuite app lets developers use the models in text and chat modalities in a web interface, it has a prompt database table tool, and you can make API keys for the PaLM 2 models.
At the time of publication, Google’s terms does not allow the PaLM API via MakerSuite to be used in production, only for prototyping.
The Codey models do not appear to be available through MakerSuite or the API.
-
Enterprise
- Google’s Cloud division offers PaLM 2 and Codey models through their Vertex AI platform.
You can experiment and prototype with the models in console services called Model Garden and Generative AI Studio (under the Vertex AI umbrella).
Advanced features like code auto-execution and generative vision services are waitlist-gated to their Trusted Tester Program for now.
You can check the status of compliance certifications for their generative AI products.
Analysis
A bet on Google is really a bet that the coming Gemini model will meet or outperform GPT-4 and GPT-3.5-Turbo in terms of capabilities and costs, along with more advanced multi-modal (images and video input) capabilities. There’s reason to believe this, since the Deepmind team is working on that model, and they have the world-class talent and experience to be capable of this.
Here are the considerations I can think of in favor of Google:
- PaLM 2 advantages
- Trained on data up to early 2023, so it will know more recent information.
- Multilingual use case advantage - the PaLM 2 models are likely to perform better here due to targeted, multilingual training.
- High caliber talent and abundant resources.
- Google integrating the Deepmind team with the Brain team should yield new state-of-the-art performance in upcoming models. We know Gemini is coming, and that is a Deepmind product.
- Virtually unlimited research and development resources on hand.
- No startup death risk.
- Google’s granular approach to language models are novel.
- There are models for general purpose language tasks and there are models for code. And within that split, there are completion and chat versions.
- OpenAI and Anthropic seems to be committing to serving just two general purpose chat models.
- Google intends to provide highly-specialized models for regulated industries. A medical use-case model, Med-PaLM-2, in under development.
- There are models for general purpose language tasks and there are models for code. And within that split, there are completion and chat versions.
And here are the factors working against them.
- Google’s PaLM 2 and Codey models are not the state-of-the-art.
- These models seem to cap out at GPT-3.5-Turbo performance.
- Their models are lacking in input context length. This puts Google in forth place against Anthropic, OpenAI, and Microsoft on this capability.
- They do not have a function calling finetuned model off-the-shelf. (You can finetune for this however).
- The PaLM 2 and Codey models are likely to be put on a 6 month depreciation schedule when the Gemini model is launched (expected around quarter 4 2023). So even if they are adequate for your uses, you’re at risk of needing to refactor your prompts on an aggressive timeline.
- No quota / rate limit advantage despite having Google-scale infrastructure.
- Current limits are 60 requests per minute for their primary text and chat bison models, while the Codey models are an appalling 15.
- If you assume 60 RPM at an average token usage per request of 4k (50% of the model’s capacity), then you would get 240k tokens per minute, equivalent to Microsoft’s quota for GPT-3.5-turbo. The max tokens-per-minute is 480k, so there is a higher ceiling here - but a 60 request limit is still hilariously low.
- You are able to request a quota increase.
- You can see their quotas here.
- Long-term commitment risk
- Google launches and tests many products, but has shown a lack of will to maintain and grow them. Reportedly a problem with their corporate culture - big launches are praised and rewarded, growth and maintenance are not. High performers optimize for launches, then abandon those projects when they achieve it.
- Google is sensitive to Wallstreet pressure and their short-term expectations. Add this with point 3 and we have a scenario where Google’s commitment on AI language models can wane if investor sentiment shifts.
Company resources:
- Document links for Vertex AI
- Generative AI docs (overview)
- Codey API docs (code generation models)
- Google’s prompt design doc
- Quotas
- Document links for Google AI
- Main product pages
Anthropic
Anthropic is a US-based AI research startup founded in 2021 by several of OpenAI’s staff. They are past their series C round, having raised over $1.6 billion in total to date.
Anthropic is focused on language model development with a strong emphasis on safety. This emphasis is everywhere in their marketing, but this doesn’t distinguish them since none of their competitors are neglecting safety.
But their language models are notable enough to be worth having in this guide as a consideration for developers.
Anthropic’s AI language models
Anthropic provides three language models, Claude 2, Claude Instant, and Claude 1.3 (which is depreciated).
What distinguishes Claude 2 and Claude Instant is their industry-leading context size, both at ~100,000 tokens (about 75,000 words), while being close to parity in capabilities with OpenAI’s state-of-the-art. These models are also on the cost efficient side of their respective class.
Claude 2 is intended for use cases that require the highest capabilities in spite of its higher expense and latency. This is their GPT-4.
Claude Instant is their cost-efficient model in the class of GPT-3.5-turbo.
Claude 2
- Anthropic’s most capable model.
- Modalities: chat.
- Use cases: general purpose writing and reasoning tasks, coding, creative literary tasks.
- Pricing: $11.02 (input), $32.68 (output) per million tokens.
- Accessible through a developer console and API.
- Other considerations:
- No internet access. No plug-ins. No alternative modalities.
- Expect higher latency than Claude Instant.
- Technical Document: Model card and evalutation
Claude Instant
- Their affordable, high-throughput model.
- Modalities: chat.
- Use cases: cost-effective, and simple, general purpose writing and reasoning tasks.
- Pricing: $1.63 (input), $5.51 (output) per million tokens.
- Accessible through a developer console, and API.
- Other considerations:
- No internet access. No plug-ins. No alternative modalities.
- Faster latency than Claude 2.
- For a model card and evaluation document, see Claude 2.
Consumer applications
- claude.ai — Their ChatGPT competitor. It reportedly uses the Claude instant model.
Analysis
Anthropic is a notable contender in the industry for these reasons:
- Their primary models have the largest input context / token capacity in the industry. About 96,000 input tokens allowable for Claude 2 and Claude Instant, a 3x improvement on the nearest competitor.
- Their models are more cost-effective than OpenAI and Microsoft’s language models. Since they have close to state-of-the-art performance in their best model, the cost-to-performance ratio here is competitive.
- Their model’s knowledge cut-off date is more recent than OpenAI’s models (early 2023 versus September 2021), meaning it will have more knowledge of recent events and facts.
But Anthropic has several factors working against them.
- Startup risk.
- Anthropic is severely out-funded. OpenAI has $10 billion from Microsoft - that’s an 11x ratio from what they’ve raised this year. Microsoft, Google, and Meta have billions in reliable cashflow to tap for AI investment.
- They’re only two years old but have raised a lot of rounds this year. This could mean they are burning cash fast and are struggling to keep up with the capital demands of the business.
- If Anthropic folds, any company that built on its models will have to eat a prompt and pipeline refactor to move to another service.
- To side with Anthropic, developers have to justify not siding with Google or Microsoft/ OpenAI, which don’t bare similar startup risks (sans OpenAI).
- Not generally available. Lack of resources.
- Developers must go through an application and waitlist to get access to their API.
- They seem as severely resource constrained as everyone else.
- They are behind on the modality and feature race.
- Anthropic only has the chat modality and no extra features that distinguish them.
- They seem overbearingly focused on AI safety.
- No competitor is overlooking safety, and their models hold no perceptible performance edge in safety either, so this isn’t a distinguishing factor.
- This focus can come at the expense of focusing on increasing raw general performance and feature expansion.
- No proprietary data source for training.
- This means they can’t confer any edge from their model pre-training.
- Juxtapose this to Microsoft (and likely OpenAI), whom has all of Github’s repositories at their disposal for code training. While Google has several apps with conversational data, and youtube for video training, and Colaboratory for code, and the best scraping infrastructure in the world.
Company resources
What’s hype
AI agents
AI agents are the application of language models in autonomous, task-doing form - by instructing a task in the first prompt, and using code to make the model re-prompt itself, appended with some form of feedback from its actions, in a loop.
So far, no attempt at this works. GPT-4 agents usually get stuck in a never-ending loop of thinking about how to do something, or they make an error in reasoning that branches it down a path that can’t complete the given task.
There’s intrigue in the idea, because an autonomous AI that’s capable enough to carry out a series of tasks makes sense as the next big step in AI technology.
But for now, we are in the ‘GPT-2’ realm of autonomous AI agents.
AI existential risk
Yes, I’m going to say it. Today, this is hype.
I know I’m hedging myself by appending ‘today’, I’m not claiming 100% future-predicting power.
But the engineer (and entrepreneur) in me knows how silly it is just extrapolate in a straight (or exponential) line. It’s always harder than you think it is. It always takes longer than you think it should. Because the last 10% of a thing, tends to take 90% of the time and energy. Exhibit A: fully self-driving cars.
We have to cross the harmless chasm of AI agents being able to do simple virtual assistant / Fivver tasks, before we get to John von Neumann demi-gods.
AI agents can’t do anything yet, despite GPT-4 tier language models seeming impressive in chatbot form.
So it’s too early to panic. Should the topic exist in the discourse? Sure. But panic is a strong emotion. It doesn’t beget logical thinking and actions. And panic is how the mainstream discourse has been devolving.
You might as well panic about the possibility of a violent, interstellar alien race finding our radio signals and extincting us.
